Originally written by Paul Masurel, co-founder of Quickwit.
The problem
For reasons that are outside of the scope of this blog post, I recently had to measure how fast one CPU-core can go through an unsorted list of unsigned 32-bit integers (u32) and output the sorted list of indexes at which the value is within a given interval.
In other words, let's say we get years as an input
[1992, 2018, 1934, 2002, 2022, 1998, 1972, 1996].
Given the interval [1982..2000], we identify that the values within the interval are
[1992, _, _, _, _, 1998, _, 1996]
Our output should therefore be their respective indexes
[0, 5, 7].
In idiomatic rust, such a function could probably look like this
use std::ops::RangeInclusive;
pub fn filter_vec_scalar(
input: &[u32],
range: RangeInclusive<u32>,
output: &mut Vec<u32>)
{
output.clear();
output.reserve(input.len());
output.extend(
input
.iter()
.enumerate()
.filter(|&(_, el)| range.contains(el))
.map(|(id, _)| id as u32),
);
}
This code seems quite trivial. Surely rustc will manage to vectorize this on its own and this will be a very short blog post, right? Well, not really no.
The generated assembly code is not a fun read (godbolt.org/z/x3sK4fvhP), so I won't show it here... but trust me on this. This is just boring scalar code.
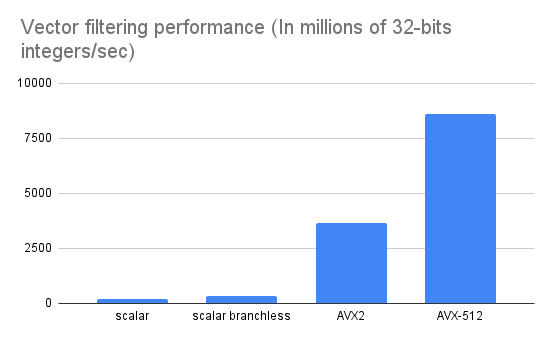
On a EC2 c5n.large instance (Intel Xeon Platinum 3 GHz (Skylake 8124)), with 50% elements being retained, this code has a throughput of 170 millions of u32s/secs.
By the end of this blog post, our code will be 20 times faster.
This blog post will show how one can use SIMD instructions to optimize this code and highlight differences between AVX2 and AVX512.
Branchless
You are eager to jump into SIMD code... I don't blame you. We will get there. As an intermediary step, however, let's see if we can improve this scalar code.
As we have seen in my previous blog post, branch misprediction can really kill CPU performance. If our data is pretty balanced and random, it can still be useful to tweak our code in order to remove branches.
The trick is easy. We will always copy our id at the tail of the output vector, but we will only increment the tail pointer if we actually want to retain this id. Our code now looks like this.
pub fn filter_vec_nobranch(
input: &[u32],
range: RangeInclusive<u32>,
output: &mut Vec<u32>) {
output.clear();
output.resize(input.len(), 0u32);
let mut output_len = 0;
for (id, &el) in input.iter().enumerate() {
output[output_len] = id as u32;
output_len += if range.contains(&el) { 1 } else { 0 };
}
output.truncate(output_len);
}
Note that I resisted the siren's call of using unsafe code here. It would probably not be that helpful anyway.
Our new code now clocks at 300 millions of u32s/secs.
AVX2
As you probably know, CPUs usually offer special instructions that operate on several pieces of data all at once. These instructions have been released over the years in "instruction sets".
An instruction set operates on a specific register with a given bit width. For instance, SSE2 works on 128-bits registers. Some instructions will treat such a register as 8x16 bits integers, some instructions will treat this register as 4x32-bits integers, etc.
As a programmer, we usually do not explicitly write assembly. Instead, we call built-in functions called intrinsics. The compiler then takes care of emitting the right assembly instructions on our behalf. In the following, I will sometimes use the instruction name and sometimes the intrinsics name. Don't worry, I am just trying to confuse you.
AVX2 is a reasonable target for our little problem: nowadays AVX/AVX2 is widely supported across 64bits x86 CPU. Most x86 Cloud VM will support this instruction set and you can expect everyone's AMD or Intel laptop to handle it. It operates over 256-bits registers.
Let's hide the gruesome instructions details behind a couple of well named function, and let's draft the idea behind our SIMD implementation.
// We store 8x32-bits integers in one 256 bits register.
const NUM_LANES: usize = 8;
pub fn filter_vec_avx2(
input: &[u32],
range: RangeInclusive<u32>,
output: &mut Vec<u32>) {
let mut output_tail = output;
assert_eq!(input.len() % NUM_LANES, 0);j
// As we read our input 8 ints at a time, we will store
// their respective indexes in `ids`.
let mut ids: __m128i = from_u32s([0, 1, 2, 3, 4, 5, 6, 7]);
const SHIFT: __m128i = from_u32s([NUM_LANES as u32; NUM_LANES]]);
for _ in 0..input.len() / 8 {
// Load 8 ints into our SIMD register.
let els: __m256i = load_unaligned(input[i * 8..].as_ptr());
// Identify the elements in the register that we
// want to keep as 8-bit bitset.
let keeper_bitset: u8 = compute_filter_bitset(els, range);
// Compact our elements, putting all of the elements
// retained on the left.
let filtered_els: __m256i = compact(els, keeper_bitset);
// Write all our 8 elements into the output...
store_unaligned(output_tail, filtered_els);
let added_len = keeper_bitset.count_ones();
output_tail = output_tail.offset(added_len);
idx = op_add(ids, SHIFT);
}
let output_len = output_tail.offset_from(output) as usize;
output.set_len(output_len);
}
Let's unpack this.
Quite expectedly, we use the same trick as in the branchless solution.
At each loop iteration, we load and store one SIMD register worth of data, that is 8-integers.
However, we increment the output_tail pointer depending on the number of retained elements.
We maintain the ids of our current consecutive 8 elements
in a 256-bits register.
We then need a way to
- identify the set of values we want to retain, and return that as an 8-bit
bitset. We called this operation
compute_filter_bitset. - move the values retained by that bitset, and move them to the left of our register. We called that operation
compact.
Unfortunately, AVX2 does not offer any obvious ways to implement
compute_filter_mask, nor compact. That's where the funs begins.
SIMD programming really feels like playing lego with a bag of oddly shaped lego bricks. Intel has a very nice reference website listing the different instructions available.
That's a long list. Let's see if we can filter this list to make it more digestible for us.
While the register can be used as well for floating point operations or integer operations, the intrinsics will refer to the associated datatype as __m256i in integer operations. That's a good keyword for us (irony incoming!).
Compact
Let's start with compact.
AVX2 does not exactly have an instruction for this. In the 128-bits world,
PSHUFB is a powerful instruction that
lets you apply a permutation over the bytes of your register.
That instruction is everyone's most popular toy. Not only is it incredibly versatile, but it also has a throughput of 1 AND a latency of 1.
Unfortunately, AVX2's grimoire of instructions does not contain such a thing.
The equivalent instruction exists and is called vpshufd, but there is a catch: it only
applies two disjoint permutations within the two 128-bits lanes, which is perfectly useless to us.
This is a very common pattern in AVX2 instructions. Instructions crossing that dreaded 128bit-lane are seldom.
It is a common source of headaches for developers.

Fortunately, applying a permutation over u32s (which is what we need) is actually possible,
via the VPERMPS instruction __mm256_permutevar8x32_epi32.
That instruction has a larger latency than PSHUB (it has a latency of 3), but this did not seem to impact our overall throughput.
Another problem that we have is that it expects a mapping as an input, while what we have in our hands is a bitset.
We need some way to efficiently convert our keeper_bitsets into the mapping our instruction expects.
This is a common problem with a common solution. Our 8-bit bitmask can only take 256 values, so we can simply precompute this mapping in an array of 256 values and ship it with the code. Converting a bitset into a mapping will then just consist of a lookup.
Our code now looks as follows:
const BITSET_TO_MAPPING: [__m256i] = /* ... */;
#[inline]
unsafe fn compact(data: __m256i, mask: u8) -> DataType {
let vperm_mask = BITSET_TO_MAPPING[mask as usize];
_mm256_permutevar8x32_epi32(data, vperm_mask)
}
At this point, we still have to declare our declare const BITSET_TO_MAPPING array of __m256i, but rust does not give us a way to write a literal for it.
Fortunately, @burntsushi (thanks) is sharing the workaround in the rust-lang github issue. The trick is to reinterpret a (non-tagged) union for this.
const fn from_u32x8(vals: [u32; 8]) -> __m256i {
union U8x32 {
vector: DataType,
vals: [u32; __m256i],
}
unsafe { U8x32 { vals }.vector }
}
compute_filter_bitset
Compute filter bitset is strangely the one that caused me the most trouble.
In AVX256, it is possible to compare 8 pairs of i32s at a time, using the use _mm256_cmpgt_epi32 intrinsics.
First speed bump: we would have preferred to compare unsigned ints. For my use case, I did not need to support the full range of u32s, so I just added an assert in the code to restrict values to 0..i32::MAX
I believe a common workaround is to flip the most significant bit before the comparison using a xor.
This operation indeed is a monotonic mapping from u32 to i32.
Second speed bump, our operator is actually strictly greater and we would have preferred greater or equal. I ended up using the negation on the mask to deal with this problem. $$\neg \left(a > b \right) \Leftrightarrow a \leq b$$
The last problem is that the output of the __mm256_cmpgt_epi32 is not a 8 bit mask.
Instead, it leaves us with a __m256 value where all the bits in a given 32 bit lane are 1 if the
left operand was great than the right operand for this given lane.
I could not find an operation to gather a single bit off each lane to form my single byte mask.
I used _mm256_movemask_epi8 to gather the msb of all bytes and then had a few lines of scalar code
to extract my 8-bits mask 32-bits integer off this integer. It was slow and felt lame. Surely there was a better way.
Then I did what every sane engineer should do. I asked Twitter (Ok I am lying a bit, at the time of the tweet I was playing with SSE2).
The tweet unfolds in a magical thread, in which many developers started sharing their tricks. If you are as old as I am, you might remember the beginning of the internet. In France, Internet providers were running commercials to let you how the internet -not their service in particular- was awesome. That thread has the same vibes as these commercials.
Eventually, Geoff Langdale jumped in with the perfect answer. The perfect instruction exists. An instruction that extracts the most significant off our 8 x 32 bits lanes and returns a single byte. The instruction is called VMOVMSKPS. I could not find it because it is presented as a floating point instruction to extract the sign of a bunch of 32-bits floats.
Of course, I had not thought of looking into the float intrinsics!
Big shoutout to Geoff. If you read this far, you should probably have a look at his amazing crafty blog in which he discusses CPU optimization and SIMD programming.
Here is our function in the end.
unsafe fn compute_filter_bitset(
val: __m256i,
range: RangeInclusive<__m256i>) -> u8 {
let too_low = op_greater(*range.start(), val);
let too_high = op_greater(val,*range.end());
let outside: _m256 = transmute::<_m256i, _m256>(op_or(too_low, too_high));
255u8 - _mm256_movemask_ps(outside) as u8
}
Putting everything together
use std::arch::x86_64::_mm256_add_epi32 as op_add;
use std::arch::x86_64::_mm256_cmpgt_epi32 as op_greater;
use std::arch::x86_64::_mm256_lddqu_si256 as load_unaligned;
use std::arch::x86_64::_mm256_storeu_si256 as store_unaligned;
use std::arch::x86_64::_mm256_or_si256 as op_or;
use std::arch::x86_64::_mm256_set1_epi32 as set1;
use std::arch::x86_64::_mm256_movemask_ps as extract_msb;
use std::arch::x86_64::_mm256_permutevar8x32_epi32 as permute;
use std::arch::x86_64::{__m256, __m256i};
use std::ops::RangeInclusive;
use std::mem::transmute;
const NUM_LANES: usize = 8;
pub fn filter_vec(
input: &[u32],
range: RangeInclusive<u32>,
output: &mut Vec<u32>) {
assert_eq!(input.len() % NUM_LANES, 0);
// We restrict the accepted boundary, because unsigned integers & SIMD don't
// play well.
let accepted_range = 0u32..(i32::MAX as u32);
assert!(accepted_range.contains(range.start()));
assert!(accepted_range.contains(range.end()));
output.clear();
output.reserve(input.len());
let num_words = input.len() / NUM_LANES;
unsafe {
let output_len = filter_vec_avx2_aux(
input.as_ptr() as *const __m256i,
range,
output.as_mut_ptr(),
num_words,
);
output.set_len(output_len);
}
}
unsafe fn filter_vec_avx2_aux(
mut input: *const __m256i,
range: RangeInclusive<u32>,
output: *mut u32,
num_words: usize,
) -> usize {
let mut output_tail = output;
let range_simd =
set1(*range.start() as i32)..=set1(*range.end() as i32);
let mut ids = from_u32x8([0, 1, 2, 3, 4, 5, 6, 7]);
const SHIFT: __m256i = from_u32x8([NUM_LANES as u32; NUM_LANES]);
for _ in 0..num_words {
let word = load_unaligned(input);
let keeper_bitset = compute_filter_bitset(word, range_simd.clone());
let added_len = keeper_bitset.count_ones();
let filtered_doc_ids = compact(ids, keeper_bitset);
store_unaligned(
output_tail as *mut __m256i,
filtered_doc_ids,
);
output_tail = output_tail.offset(added_len as isize);
ids = op_add(ids, SHIFT);
input = input.offset(1);
}
output_tail.offset_from(output) as usize
}
#[inline]
unsafe fn compact(data: __m256i, mask: u8) -> __m256i {
let vperm_mask = BITSET_TO_MAPPING[mask as usize];
permute(data, vperm_mask)
}
#[inline]
unsafe fn compute_filter_bitset(
val: __m256i,
range: RangeInclusive<__m256i>) -> u8 {
let too_low = op_greater(*range.start(), val);
let too_high = op_greater(val,*range.end());
let outside: __m256 = transmute::<__m256i, __m256>(op_or(too_low, too_high));
255u8 - extract_msb(outside) as u8
}
const fn from_u32x8(vals: [u32; NUM_LANES]) -> __m256i {
union U8x32 {
vector: __m256i,
vals: [u32; NUM_LANES],
}
unsafe { U8x32 { vals }.vector }
}
const BITSET_TO_MAPPING: [__m256i; 256] = [
from_u32x8([0, 0, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 0, 0, 0, 0, 0, 0, 0]),
from_u32x8([1, 0, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 0, 0, 0, 0, 0, 0]),
from_u32x8([2, 0, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 0, 0, 0, 0, 0, 0]),
from_u32x8([1, 2, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 0, 0, 0, 0, 0]),
from_u32x8([3, 0, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 0, 0, 0, 0, 0, 0]),
from_u32x8([1, 3, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 0, 0, 0, 0, 0]),
from_u32x8([2, 3, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 0, 0, 0, 0, 0]),
from_u32x8([1, 2, 3, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 0, 0, 0, 0]),
from_u32x8([4, 0, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 4, 0, 0, 0, 0, 0, 0]),
from_u32x8([1, 4, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 4, 0, 0, 0, 0, 0]),
from_u32x8([2, 4, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 4, 0, 0, 0, 0, 0]),
from_u32x8([1, 2, 4, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 4, 0, 0, 0, 0]),
from_u32x8([3, 4, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 4, 0, 0, 0, 0, 0]),
from_u32x8([1, 3, 4, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 4, 0, 0, 0, 0]),
from_u32x8([2, 3, 4, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 4, 0, 0, 0, 0]),
from_u32x8([1, 2, 3, 4, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 4, 0, 0, 0]),
from_u32x8([5, 0, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 5, 0, 0, 0, 0, 0, 0]),
from_u32x8([1, 5, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 5, 0, 0, 0, 0, 0]),
from_u32x8([2, 5, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 5, 0, 0, 0, 0, 0]),
from_u32x8([1, 2, 5, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 5, 0, 0, 0, 0]),
from_u32x8([3, 5, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 5, 0, 0, 0, 0, 0]),
from_u32x8([1, 3, 5, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 5, 0, 0, 0, 0]),
from_u32x8([2, 3, 5, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 5, 0, 0, 0, 0]),
from_u32x8([1, 2, 3, 5, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 5, 0, 0, 0]),
from_u32x8([4, 5, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 4, 5, 0, 0, 0, 0, 0]),
from_u32x8([1, 4, 5, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 4, 5, 0, 0, 0, 0]),
from_u32x8([2, 4, 5, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 4, 5, 0, 0, 0, 0]),
from_u32x8([1, 2, 4, 5, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 4, 5, 0, 0, 0]),
from_u32x8([3, 4, 5, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 4, 5, 0, 0, 0, 0]),
from_u32x8([1, 3, 4, 5, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 4, 5, 0, 0, 0]),
from_u32x8([2, 3, 4, 5, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 4, 5, 0, 0, 0]),
from_u32x8([1, 2, 3, 4, 5, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 4, 5, 0, 0]),
from_u32x8([6, 0, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 6, 0, 0, 0, 0, 0, 0]),
from_u32x8([1, 6, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 6, 0, 0, 0, 0, 0]),
from_u32x8([2, 6, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 6, 0, 0, 0, 0, 0]),
from_u32x8([1, 2, 6, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 6, 0, 0, 0, 0]),
from_u32x8([3, 6, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 6, 0, 0, 0, 0, 0]),
from_u32x8([1, 3, 6, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 6, 0, 0, 0, 0]),
from_u32x8([2, 3, 6, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 6, 0, 0, 0, 0]),
from_u32x8([1, 2, 3, 6, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 6, 0, 0, 0]),
from_u32x8([4, 6, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 4, 6, 0, 0, 0, 0, 0]),
from_u32x8([1, 4, 6, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 4, 6, 0, 0, 0, 0]),
from_u32x8([2, 4, 6, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 4, 6, 0, 0, 0, 0]),
from_u32x8([1, 2, 4, 6, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 4, 6, 0, 0, 0]),
from_u32x8([3, 4, 6, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 4, 6, 0, 0, 0, 0]),
from_u32x8([1, 3, 4, 6, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 4, 6, 0, 0, 0]),
from_u32x8([2, 3, 4, 6, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 4, 6, 0, 0, 0]),
from_u32x8([1, 2, 3, 4, 6, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 4, 6, 0, 0]),
from_u32x8([5, 6, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 5, 6, 0, 0, 0, 0, 0]),
from_u32x8([1, 5, 6, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 5, 6, 0, 0, 0, 0]),
from_u32x8([2, 5, 6, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 5, 6, 0, 0, 0, 0]),
from_u32x8([1, 2, 5, 6, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 5, 6, 0, 0, 0]),
from_u32x8([3, 5, 6, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 5, 6, 0, 0, 0, 0]),
from_u32x8([1, 3, 5, 6, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 5, 6, 0, 0, 0]),
from_u32x8([2, 3, 5, 6, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 5, 6, 0, 0, 0]),
from_u32x8([1, 2, 3, 5, 6, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 5, 6, 0, 0]),
from_u32x8([4, 5, 6, 0, 0, 0, 0, 0]),
from_u32x8([0, 4, 5, 6, 0, 0, 0, 0]),
from_u32x8([1, 4, 5, 6, 0, 0, 0, 0]),
from_u32x8([0, 1, 4, 5, 6, 0, 0, 0]),
from_u32x8([2, 4, 5, 6, 0, 0, 0, 0]),
from_u32x8([0, 2, 4, 5, 6, 0, 0, 0]),
from_u32x8([1, 2, 4, 5, 6, 0, 0, 0]),
from_u32x8([0, 1, 2, 4, 5, 6, 0, 0]),
from_u32x8([3, 4, 5, 6, 0, 0, 0, 0]),
from_u32x8([0, 3, 4, 5, 6, 0, 0, 0]),
from_u32x8([1, 3, 4, 5, 6, 0, 0, 0]),
from_u32x8([0, 1, 3, 4, 5, 6, 0, 0]),
from_u32x8([2, 3, 4, 5, 6, 0, 0, 0]),
from_u32x8([0, 2, 3, 4, 5, 6, 0, 0]),
from_u32x8([1, 2, 3, 4, 5, 6, 0, 0]),
from_u32x8([0, 1, 2, 3, 4, 5, 6, 0]),
from_u32x8([7, 0, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 7, 0, 0, 0, 0, 0, 0]),
from_u32x8([1, 7, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 7, 0, 0, 0, 0, 0]),
from_u32x8([2, 7, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 7, 0, 0, 0, 0, 0]),
from_u32x8([1, 2, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 7, 0, 0, 0, 0]),
from_u32x8([3, 7, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 7, 0, 0, 0, 0, 0]),
from_u32x8([1, 3, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 7, 0, 0, 0, 0]),
from_u32x8([2, 3, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 7, 0, 0, 0, 0]),
from_u32x8([1, 2, 3, 7, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 7, 0, 0, 0]),
from_u32x8([4, 7, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 4, 7, 0, 0, 0, 0, 0]),
from_u32x8([1, 4, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 4, 7, 0, 0, 0, 0]),
from_u32x8([2, 4, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 4, 7, 0, 0, 0, 0]),
from_u32x8([1, 2, 4, 7, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 4, 7, 0, 0, 0]),
from_u32x8([3, 4, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 4, 7, 0, 0, 0, 0]),
from_u32x8([1, 3, 4, 7, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 4, 7, 0, 0, 0]),
from_u32x8([2, 3, 4, 7, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 4, 7, 0, 0, 0]),
from_u32x8([1, 2, 3, 4, 7, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 4, 7, 0, 0]),
from_u32x8([5, 7, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 5, 7, 0, 0, 0, 0, 0]),
from_u32x8([1, 5, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 5, 7, 0, 0, 0, 0]),
from_u32x8([2, 5, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 5, 7, 0, 0, 0, 0]),
from_u32x8([1, 2, 5, 7, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 5, 7, 0, 0, 0]),
from_u32x8([3, 5, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 5, 7, 0, 0, 0, 0]),
from_u32x8([1, 3, 5, 7, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 5, 7, 0, 0, 0]),
from_u32x8([2, 3, 5, 7, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 5, 7, 0, 0, 0]),
from_u32x8([1, 2, 3, 5, 7, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 5, 7, 0, 0]),
from_u32x8([4, 5, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 4, 5, 7, 0, 0, 0, 0]),
from_u32x8([1, 4, 5, 7, 0, 0, 0, 0]),
from_u32x8([0, 1, 4, 5, 7, 0, 0, 0]),
from_u32x8([2, 4, 5, 7, 0, 0, 0, 0]),
from_u32x8([0, 2, 4, 5, 7, 0, 0, 0]),
from_u32x8([1, 2, 4, 5, 7, 0, 0, 0]),
from_u32x8([0, 1, 2, 4, 5, 7, 0, 0]),
from_u32x8([3, 4, 5, 7, 0, 0, 0, 0]),
from_u32x8([0, 3, 4, 5, 7, 0, 0, 0]),
from_u32x8([1, 3, 4, 5, 7, 0, 0, 0]),
from_u32x8([0, 1, 3, 4, 5, 7, 0, 0]),
from_u32x8([2, 3, 4, 5, 7, 0, 0, 0]),
from_u32x8([0, 2, 3, 4, 5, 7, 0, 0]),
from_u32x8([1, 2, 3, 4, 5, 7, 0, 0]),
from_u32x8([0, 1, 2, 3, 4, 5, 7, 0]),
from_u32x8([6, 7, 0, 0, 0, 0, 0, 0]),
from_u32x8([0, 6, 7, 0, 0, 0, 0, 0]),
from_u32x8([1, 6, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 1, 6, 7, 0, 0, 0, 0]),
from_u32x8([2, 6, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 2, 6, 7, 0, 0, 0, 0]),
from_u32x8([1, 2, 6, 7, 0, 0, 0, 0]),
from_u32x8([0, 1, 2, 6, 7, 0, 0, 0]),
from_u32x8([3, 6, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 3, 6, 7, 0, 0, 0, 0]),
from_u32x8([1, 3, 6, 7, 0, 0, 0, 0]),
from_u32x8([0, 1, 3, 6, 7, 0, 0, 0]),
from_u32x8([2, 3, 6, 7, 0, 0, 0, 0]),
from_u32x8([0, 2, 3, 6, 7, 0, 0, 0]),
from_u32x8([1, 2, 3, 6, 7, 0, 0, 0]),
from_u32x8([0, 1, 2, 3, 6, 7, 0, 0]),
from_u32x8([4, 6, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 4, 6, 7, 0, 0, 0, 0]),
from_u32x8([1, 4, 6, 7, 0, 0, 0, 0]),
from_u32x8([0, 1, 4, 6, 7, 0, 0, 0]),
from_u32x8([2, 4, 6, 7, 0, 0, 0, 0]),
from_u32x8([0, 2, 4, 6, 7, 0, 0, 0]),
from_u32x8([1, 2, 4, 6, 7, 0, 0, 0]),
from_u32x8([0, 1, 2, 4, 6, 7, 0, 0]),
from_u32x8([3, 4, 6, 7, 0, 0, 0, 0]),
from_u32x8([0, 3, 4, 6, 7, 0, 0, 0]),
from_u32x8([1, 3, 4, 6, 7, 0, 0, 0]),
from_u32x8([0, 1, 3, 4, 6, 7, 0, 0]),
from_u32x8([2, 3, 4, 6, 7, 0, 0, 0]),
from_u32x8([0, 2, 3, 4, 6, 7, 0, 0]),
from_u32x8([1, 2, 3, 4, 6, 7, 0, 0]),
from_u32x8([0, 1, 2, 3, 4, 6, 7, 0]),
from_u32x8([5, 6, 7, 0, 0, 0, 0, 0]),
from_u32x8([0, 5, 6, 7, 0, 0, 0, 0]),
from_u32x8([1, 5, 6, 7, 0, 0, 0, 0]),
from_u32x8([0, 1, 5, 6, 7, 0, 0, 0]),
from_u32x8([2, 5, 6, 7, 0, 0, 0, 0]),
from_u32x8([0, 2, 5, 6, 7, 0, 0, 0]),
from_u32x8([1, 2, 5, 6, 7, 0, 0, 0]),
from_u32x8([0, 1, 2, 5, 6, 7, 0, 0]),
from_u32x8([3, 5, 6, 7, 0, 0, 0, 0]),
from_u32x8([0, 3, 5, 6, 7, 0, 0, 0]),
from_u32x8([1, 3, 5, 6, 7, 0, 0, 0]),
from_u32x8([0, 1, 3, 5, 6, 7, 0, 0]),
from_u32x8([2, 3, 5, 6, 7, 0, 0, 0]),
from_u32x8([0, 2, 3, 5, 6, 7, 0, 0]),
from_u32x8([1, 2, 3, 5, 6, 7, 0, 0]),
from_u32x8([0, 1, 2, 3, 5, 6, 7, 0]),
from_u32x8([4, 5, 6, 7, 0, 0, 0, 0]),
from_u32x8([0, 4, 5, 6, 7, 0, 0, 0]),
from_u32x8([1, 4, 5, 6, 7, 0, 0, 0]),
from_u32x8([0, 1, 4, 5, 6, 7, 0, 0]),
from_u32x8([2, 4, 5, 6, 7, 0, 0, 0]),
from_u32x8([0, 2, 4, 5, 6, 7, 0, 0]),
from_u32x8([1, 2, 4, 5, 6, 7, 0, 0]),
from_u32x8([0, 1, 2, 4, 5, 6, 7, 0]),
from_u32x8([3, 4, 5, 6, 7, 0, 0, 0]),
from_u32x8([0, 3, 4, 5, 6, 7, 0, 0]),
from_u32x8([1, 3, 4, 5, 6, 7, 0, 0]),
from_u32x8([0, 1, 3, 4, 5, 6, 7, 0]),
from_u32x8([2, 3, 4, 5, 6, 7, 0, 0]),
from_u32x8([0, 2, 3, 4, 5, 6, 7, 0]),
from_u32x8([1, 2, 3, 4, 5, 6, 7, 0]),
from_u32x8([0, 1, 2, 3, 4, 5, 6, 7]),
];
Our AVX2 code clocks at 3.65 billions of elements per second. Sweet. This is actually 8 times faster than the branchless scalar solution.
AVX-512 to the rescue
Recent Intel CPUs and the upcoming AMD Zen 4 CPUs handle a new instruction set called AVX-512. It operates over 16 x 32-bits integers at a time.
But AVX-512 is not just about doubling the number of lanes to play with! It adds a lot of new instructions to make our life easier.
For instance, _mm512_cmple_epi32_mask is an intrinsics that compares the 16 x 32 bits integers
of two __m512i. The output is now exactly what we expected: it's a 16-bit bitset.
What about compression, and our ugly map? AVX-512 comes with an instruction (the intrinsics is called _mm512_mask_compressstoreu_epi32) that does exactly what we want!
use std::arch::x86_64::_mm512_add_epi32 as op_add;
use std::arch::x86_64::_mm512_cmple_epi32_mask as op_less_or_equal;
use std::arch::x86_64::_mm512_loadu_epi32 as load_unaligned;
use std::arch::x86_64::_mm512_set1_epi32 as set1;
use std::arch::x86_64::_mm512_mask_compressstoreu_epi32 as compress;
use std::arch::x86_64::__m512i;
use std::ops::RangeInclusive;
const NUM_LANES: usize = 16;
pub fn filter_vec(input: &[u32], range: RangeInclusive<u32>, output: &mut Vec<u32>) {
assert_eq!(input.len() % NUM_LANES, 0);
// We restrict the accepted boundary, because unsigned integers & SIMD don't
// play well.
let accepted_range = 0u32..(i32::MAX as u32);
assert!(accepted_range.contains(range.start()));
assert!(accepted_range.contains(range.end()));
output.clear();
output.reserve(input.len());
let num_words = input.len() / NUM_LANES;
unsafe {
let output_len = filter_vec_aux(
input.as_ptr(),
range,
output.as_mut_ptr(),
num_words,
);
output.set_len(output_len);
}
}
pub unsafe fn filter_vec_aux(
mut input: *const u32,
range: RangeInclusive<u32>,
output: *mut u32,
num_words: usize,
) -> usize {
let mut output_end = output;
let range_simd =
set1(*range.start() as i32)..=set1(*range.end() as i32);
let mut ids = from_u32x16([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]);
const SHIFT: __m512i = from_u32x16([NUM_LANES as u32; NUM_LANES]);
for _ in 0..num_words {
let word = load_unaligned(input as *const i32);
let keeper_bitset = compute_filter_bitset(word, range_simd.clone());
compress(output_end as *mut u8, keeper_bitset, ids);
let added_len = keeper_bitset.count_ones();
output_end = output_end.offset(added_len as isize);
ids = op_add(ids, SHIFT);
input = input.offset(1);
}
output_end.offset_from(output) as usize
}
#[inline]
unsafe fn compute_filter_bitset(
val: __m512i,
range: RangeInclusive<__m512i>) -> u16 {
let low = op_less_or_equal(*range.start(), val);
let high = op_less_or_equal(val, *range.end());
low & high
}
const fn from_u32x16(vals: [u32; NUM_LANES]) -> __m512i {
union U8x64 {
vector: __m512i,
vals: [u32; NUM_LANES],
}
unsafe { U8x64 { vals }.vector }
}
This version is considerably simpler and now runs at 8.6 billions of integers per second.

Conclusion
AVX512 is really sucking the fun out of SIMD programming. My code ended up being both considerably simpler and faster.